
Step 1. Discover Core Information
No developer wants to document things manually, especially not in a continuous delivery world. As a result, automation is the first step toward the catalogs at the core of VSM. We support our customers here in two ways:
- With out-of-the-box integrations, you can get started extracting your data within minutes. It could be a plugin (e.g. for Jenkins), it could be a scheduled job hosted by us
- With powerful APIs that enable you to build your integrations and leverage our platform capabilities to monitor them & keep them up-to-date.
Create your service baseline
The center of automated VSM data is the service catalog. To get you started fast and efficiently, we look to automate a scalable baseline from your code repository. Utilizing out-of-the-box integrations to Github (SaaS or OnPrem), Azure Repos, and more, we discover a full list of all the repositories managed in your organization.
The first discovery scan brings a first list into your mapping inbox. From here, you filter which discovered repos are valuable and should thus appear in your service catalog and which should not be selecting the relevant services and clicking the import button. This ensures that only valuable data lives in your catalog and remains clutter-free. Ideally, this is already done by your teams - urge them to claim their services directly from the inbox. This will ensure data accuracy and accelerate ownership mapping.
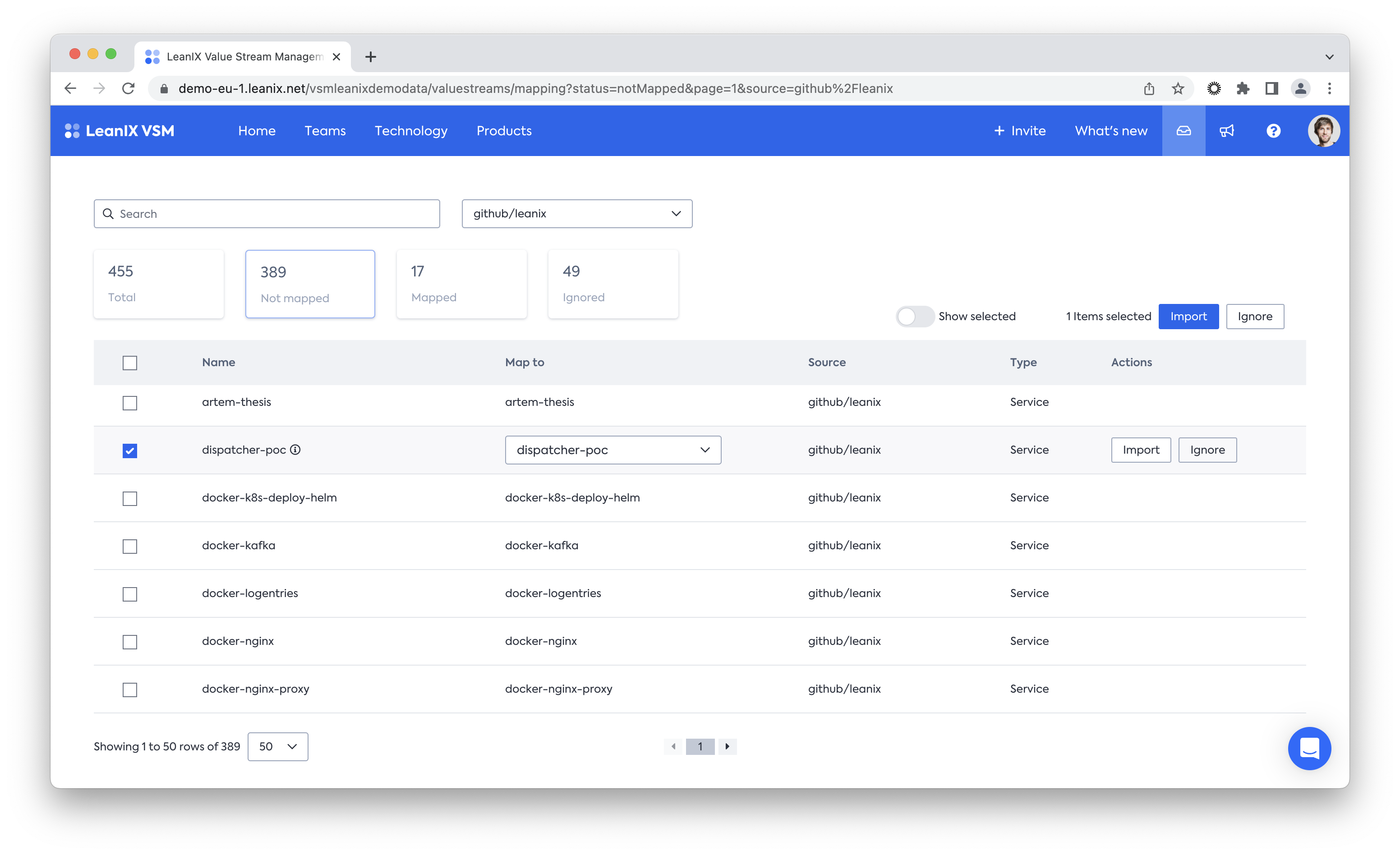
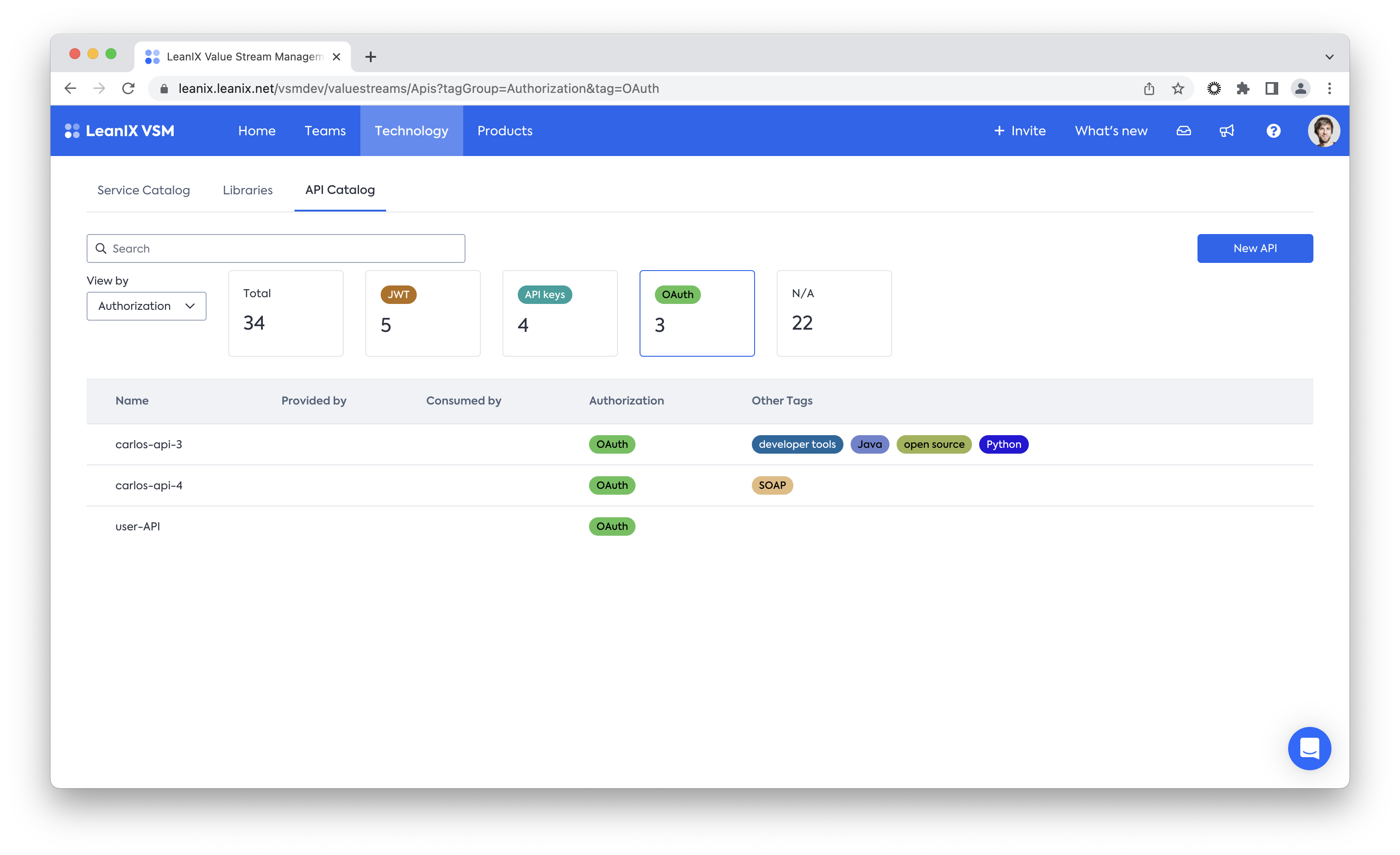
Establish your API catalog
Next to the Service Catalog, VSM captures a comprehensive and related API catalog. Combining the two allows a more sophisticated understanding of your service architecture by capturing which services are connected and how.
Here too, you should aim to discover them automatically. You can easily connect to existing systems containing API data by using VSMs REST endpoints for API data.
If none are immediately possible, there is always the manual option - either way, in the end, each team should take responsibility to accurately map one level upstream & one level downstream of their services to build a comprehensive catalog.
VSM-EAM Integration
Say hello to the Auto-Import of Products based on EAM Applications! It automatically detects products based on Application Fact Sheets in an EAM workspace that's connected to your VSM and imports them as Products. While before, you had to map these manually to products via the mapping inbox, this step is now done automatically, saving you substantial time and effort. Included features are:
Controlled mapping: You can still modify or delete the mapping via the mapping inbox, providing you with full control and flexibility.
Preserve existing Applications: The auto-import is triggered only for new applications. The mapping for applications discovered before won't be changed or overridden, preserving your previous manual decisions.
Bulk import: Click 'select all' and then apply the bulk action to implement the suggested action for all Applications.
Updated 9 months ago